Land Change Modeler is an innovative land planning and decision support system that is fully integrated into the TerrSet software. With an automated, user-friendly workflow, Land Change Modeler simplifies the complexities of change analysis. Land Change Modeler allows you to rapidly analyze land cover change, empirically model relationships to explanatory variables, and simulate future land change scenarios. Land Change Modeler also includes special tools for the assessment of REDD (Reducing Emissions from Deforestation and forest Degradation) climate change mitigation strategies. Land Change Modeler provides a start-to-finish solution for your land change analysis needs.
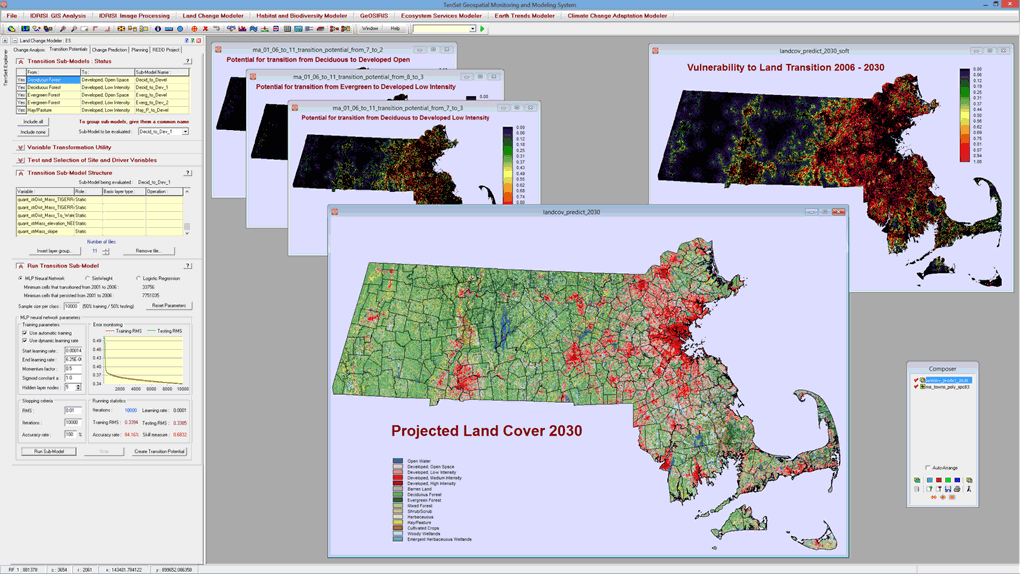
Land Change Modeler, developed with support from Conservation International to support their field offices, provides a set of tools for the rapid assessment and mapping of change. Various models exist for predicting future scenarios.
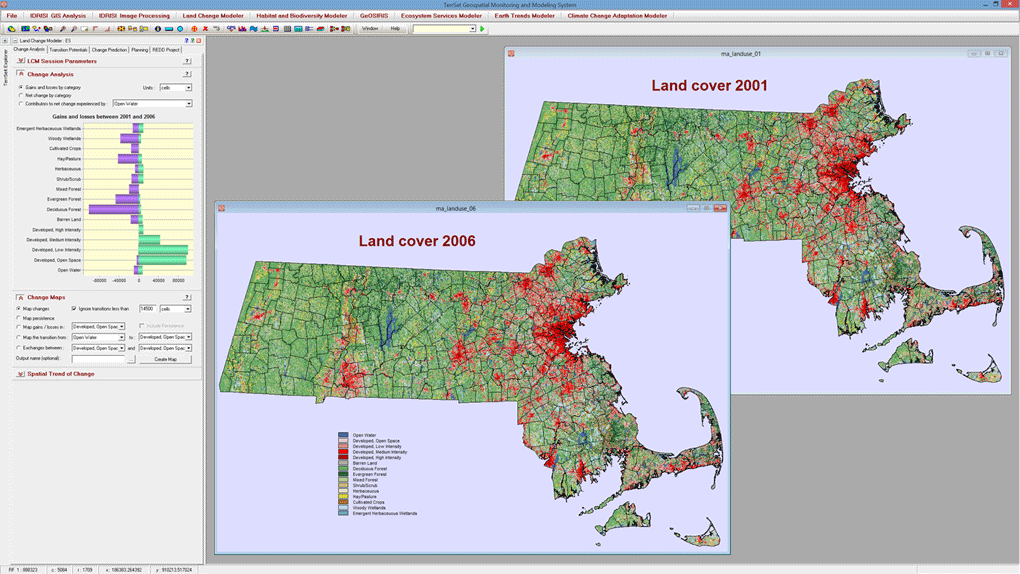
Land Change Modeler provides a set of tools for the rapid assessment and mapping of change, allowing for one-click evaluations of land cover gains and losses, net change and persistence, both in map and graphical form.
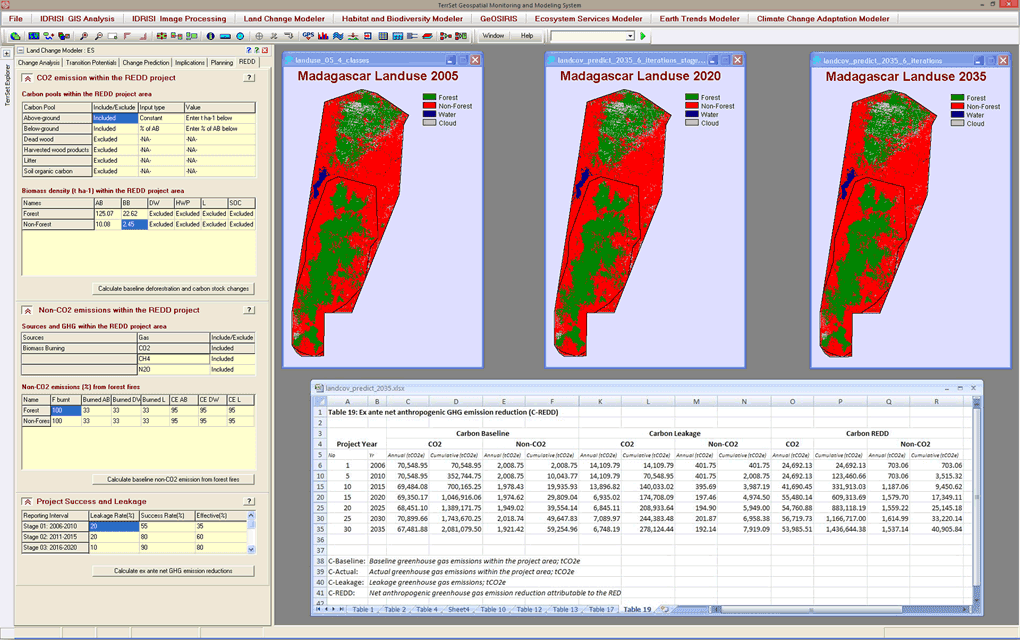
The REDD tab in LCM provides a full accounting of CO2 and non-CO2 baseline emissions for a REDD project area and the reductions that would be expected as a result of REDD project activities. A set of 19 tables are generated following the logic of the World Bank’s BioCarbon Fund methodology.

Land Change Modeler in TerrSet models land use change scenarios. The SimWeight empirical transition potential modeling procedure in LCM, based on a modified K-nearest neighbor machine learning algorithm, shown in this graphic, can be used to model these scenarios along with the Multi-Layer Perceptron neural network and logistic regression options.
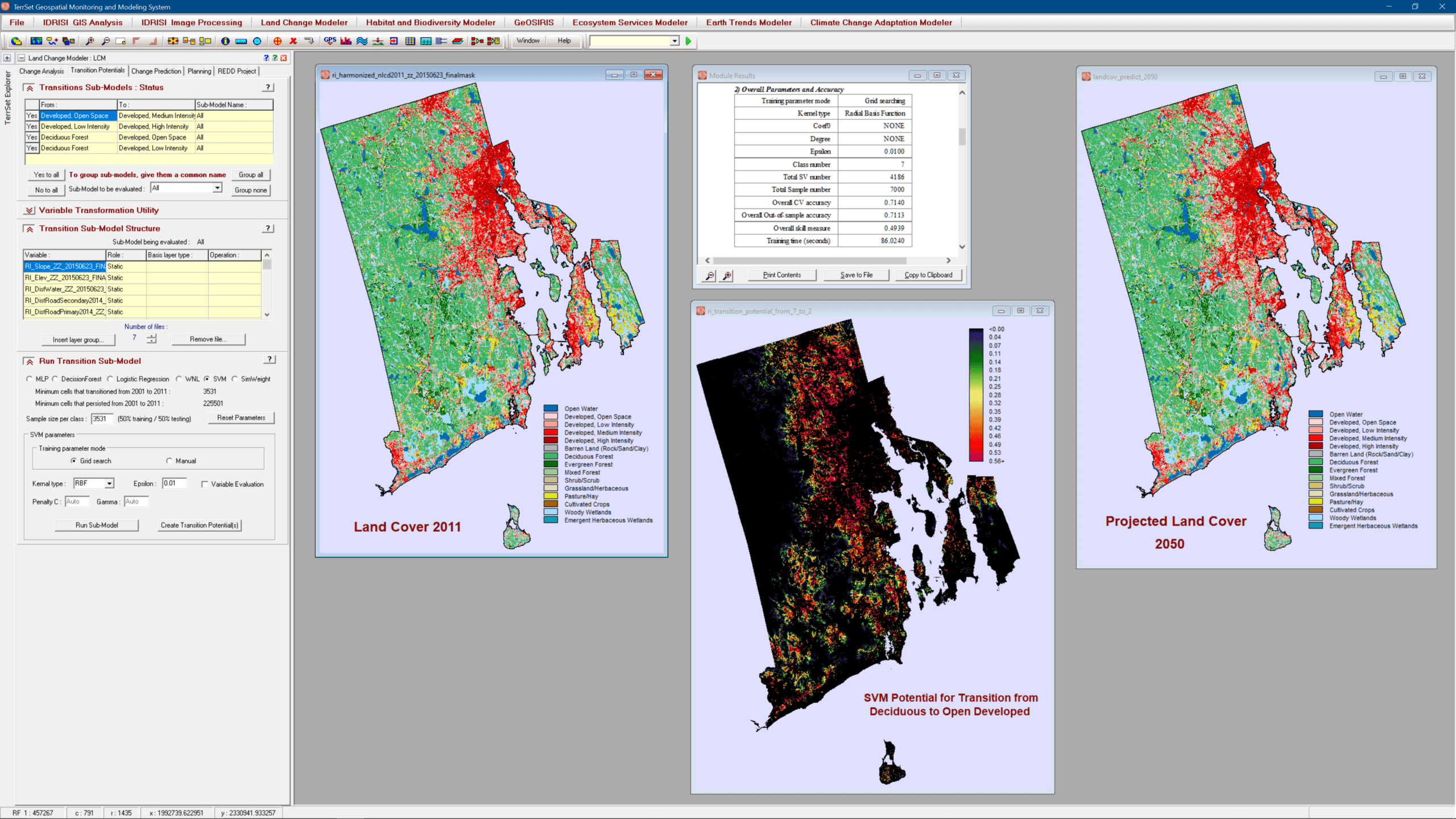
The Land Change Modeler (LCM), a mainstay of the land change, conservation, smart development and REDD (Reducing Emissions from Deforestation and forest Degradation) communities, has undergone a major reworking to enhance its stability and to provide new empirical modeling tools. Alongside the Multi-Layer Perceptron (MLP), Logistic Regression and Simweight (KNN) modeling approaches, LCM now also supports SVM (Support Vector Machine), DecisionForest (an implementation of Random Forest), and WNL (Weighted Normalized Likelihoods) – a fast modeling procedure for large numbers of transitions.
Land Change Modeler Key Features
Land Change Analysis
- Quickly generate graphs and maps of land change, including gains and losses, net change, and persistence of specific transitions.
- Uncover underlying trends of complex land change with a change abstraction tool.
Land Transition Potential Modeling
- Model land cover transition potentials that express the likelihood that land will transition in the future using one of several methodologies-a multi-layer perceptron neural network with full reporting on the explanatory power of driver variables, logistic regression, Decision Forest (Random Forest implementation), Support Vector Machine, Weighted Normalized Likelihood, and SimWeight, a modified machine-learning procedure.
- Incorporate dynamic variables that drive or explain change.
Change Prediction
- Incorporate planning interventions, incentives and constraints, such as reserve areas and infrastructural changes that may alter the course of development when modeling future scenarios.
- Conduct scenario mapping by creating either a hard prediction map based on a multi-objective land competition model with a single realization or a soft prediction map that is a continuous map of vulnerability to change.
- Validate the quality of the predicted land cover map in relation to a map of reality through a 3-way crosstabulation. Hits, misses and false alarms are reported.
REDD Analysis
- Evaluate REDD related forest conservation strategies and carbon impact scenarios with full GHG emission impact accounting.
- Assess additionality of REDD projects and business-as-usual projection scenarios.
See Bibliography for projects that cite LCM.